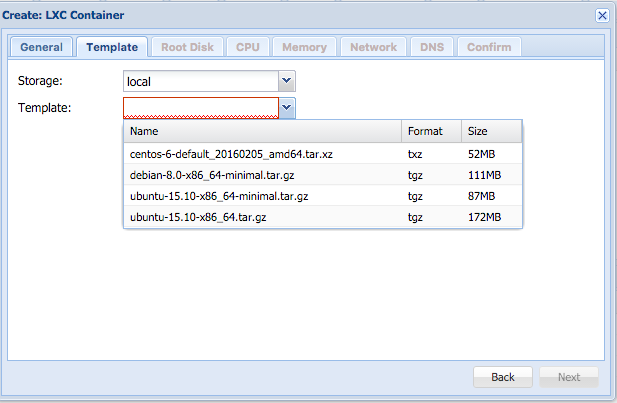
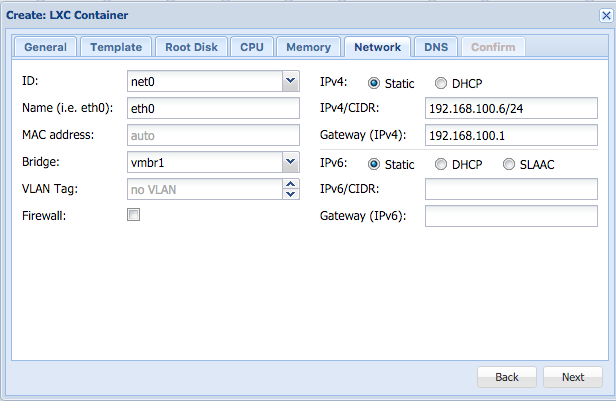
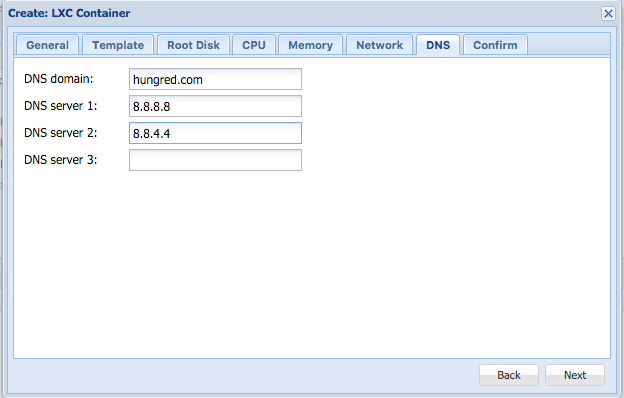
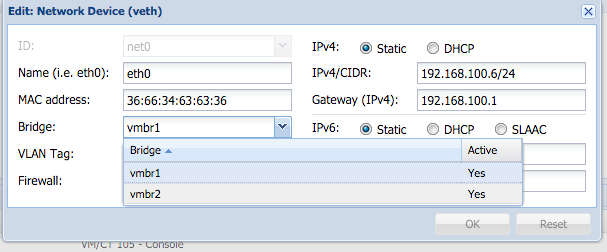
Ok, im migrating this website to another server using docker. This is how i setup my multi site with Docker Nginx and MariaDB or MySQL if you wonder. Here is what i did,
Install MariaDB / MySQL
Look for MariaDB on the offical Docker hub, we are going to install the one below,
docker run --restart=always --name mariadb -v /root/mysql:/var/lib/mysql -v /root/mysql/conf.d:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=PassWord10 -d mariadb:latest
So all our data record are located at /root/mysql with the root password as shown above using the 'latest' tag for the latest mariadb.
Install PhpMyAdmin
Now i need to manage my MySQL externally so im going to install PhpMyAdmin using the official Docker hub image i create an image with the name phpmyadmin.
docker run --restart=always --name phpmyadmin -d --link mariadb:db -p 8080:8080 phpmyadmin/phpmyadmin
The creates a phpmyadmin that links to my mariadb container using port 8080. Hence, if you are going to visit phpmyadmin, just head over to localhost:8080
Install Nginx Reverse Proxy
As for reverse proxy im using one of the open image
docker run -d -p 80:80 -p 443:443 --restart=always --name proxy -v /root/nginx/htpasswd:/etc/nginx/htpasswd -v /root/nginx/ssl:/etc/nginx/certs -v /var/run/docker.sock:/tmp/docker.sock:ro jwilder/nginx-proxy
This creates a few folder on my host machine so i could manage my virtual host and open up both port 80 and 443 for SSL enabled website.
Now to generate SSL into /root/nginx/ssl i use the following
openssl req -x509 -newkey rsa:2048 -keyout default.key -out default.crt-days 9999
and our virtual host should be able to support SSL on port 443
Install PHP+FPM
So i need PHP+FPM, hence, i added the container below using the image from the offical php but with my own DockerFile but you can use mine as shown below,
docker run -it --restart=always --name phpfpm --link mariadb:mysqlip -v /root/www:/home claylua/phpfpm
well, i keep the default name of phpfpm and i keep the dockerfile in my github.
Install Nginx
Now i need to install WordPress but before that i will need a web server and im using Nginx in this case, using the official nginx image, i run a subdomain of hungred.com
docker run
-e VIRTUAL_HOST=test.hungred.com,www.test.hungred.com
--restart=always
--name test.hungred.com
--link mariadb:mysqlip
--link phpfpm:phpfpm
-v /root/nginx/conf.d/test.hungred.com:/etc/nginx/conf.d
-v /root/nginx/ssl/test.hungred.com:/etc/nginx/ssl
-v /root/nginx/conf/test.hungred.com/nginx.conf:/etc/nginx/nginx.conf:ro
-v /root/www/test.hungred.com:/home/test.hungred.com:ro
-d -p 10295:80 nginx
Take note that the port should be different and can be anything with the path to the host at your own discrete. For each path, i am trying to create a custom installation for the web server folder and nginx configuration. Hence, for each nginx configuration on your host, do add the following nginx.conf into the path you have specific above.
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
After this we will need to do a proxy for all php files to the phpfpm container we just created previously. head over to /root/nginx/sites-available/test.hungred.com and create a new file call default and paste the following code
server {
listen 80;
listen 443 ssl;
server_name test.hungred.com;
root /home/test.hungred.com/;
location / {
index index.html index.htm index.php;
try_files $uri /index.php$is_args$args;
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_pass phpfpm:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root/$fastcgi_script_name;
}
}
And since our php files is located at /var/www/test.hungred.com/ we will just place everything there for all our php request.
Test it!
Now once you are done with the above, start all your container, restart your server, and whatever you do, make sure that everything still works perfectly for you!
*** UPDATE ***
In case you are wondering where i host my website, i am currently hosting with Digital Ocean, using their 512MB node, highly recommended and very stable so far as compare to other provider i have been with. You can choose Vulr as well, which provides you higher memory and disk space with many other options to help yous ave cost.